Landscape Classes
The first national goal of the Cohesive Strategy is to restore and maintain resilient landscapes. Landscape resiliency has been defined in various ways, but at its core are sustainability and resistance to and recovery from disturbance. Given that landscapes are complex intersections of natural, built, and human components, simple definitions or measures of landscape resiliency have limited utility. A more useful approach is to recognize that discussions about sustaining values and resiliency are contextual, that is, they vary from location to location and depend upon a host of local considerations, including both ecological and human dimensions.

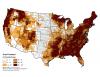
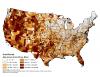
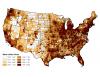
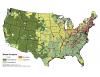
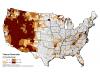
Figure 2.1The classification system designed and used here divides counties into landscape classes where similar conversations about land management objectives and resiliency might occur, using county-level attributes. Counties were assigned to different landscape classes using a classification tree. A classification tree begins with all counties in a single group and then progressively divides them into more similar subgroups based on key variables. Each junction in the classification tree involves a dichotomous division based on a single variable. The classification tree used the relative urban landcover within a county, the modal fire regime,[1] geographical region, area forested, area of public lands, and various measures of fire occurrence to assign counties to one of 11 classes labeled A through K (figure 2.1).
Figure 2.2
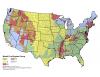
The classes tend to have strong geographical associations due to the influence of regional similarities in landcover and fire regimes (figure 2.2); a notable exception is the urban class (Class A), which follows the national pattern of population density and urban development.
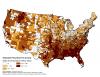
The nature of each class is revealed by looking at both the variables used in the classification tree and the broader range of descriptive variables for each county. Figure 2.3 provides an abbreviated label for each class as well as some simple comparison graphics for looking at the distributions of eight selected variables within each class. For example, landscape class D characterizes agricultural and grassland areas that are relatively devoid of forested areas or Federal ownership, 
Figure 2.3historically experienced very high levels of natural fire, and generally fall in the lower half (moderate) of the national range with respect to the four other variables. Using this and other information, one can develop an informative, general narrative that applies to the counties within each class.
Furthermore, the landscape class narratives help point to possible management options or policies that would advance the goal of landscape resiliency within each class, recognizing that each class could connote a unique interpretation of “landscape resiliency” that is specific to the conditions found therein. Thus, landscape classes are used to promote a context-specific discussion of management options that matches actions and activities to landscapes. More complete landscape class narratives and data descriptions are available online through the Cohesive Strategy data and tools library (refer to http://www.forestsandrangelands.gov/strategy/thestrategy.shtml).
Conclusion: Counties have been classified using a relatively small set of variables into various “landscape classes” that share common attributes. Examining multiple variables reveals both similarities and differences among counties relative to the theme of landscape resiliency.
[1] Historical fire regimes refer to the characteristic frequency and severity of wildfires prior to European settlement. Further discussion of fire regime can be found in the Challenges and Opportunities section.
View Individual Landscape Classes
Input Variables
Data sets used in a statistical analysis or classification methodology to produce the variable above.